12.7 million Americans now covered by private insurers because of ACA
Most have never had insurance coverage until ACA/Obamacare
The insurance enrollment process is challenging when factoring in chronic conditions, care provider relationships and drug coverage
If you have employer-provided coverage think about what it's like for you every year for enrollment
Comparing insurance plans for what really matters is almost impossible
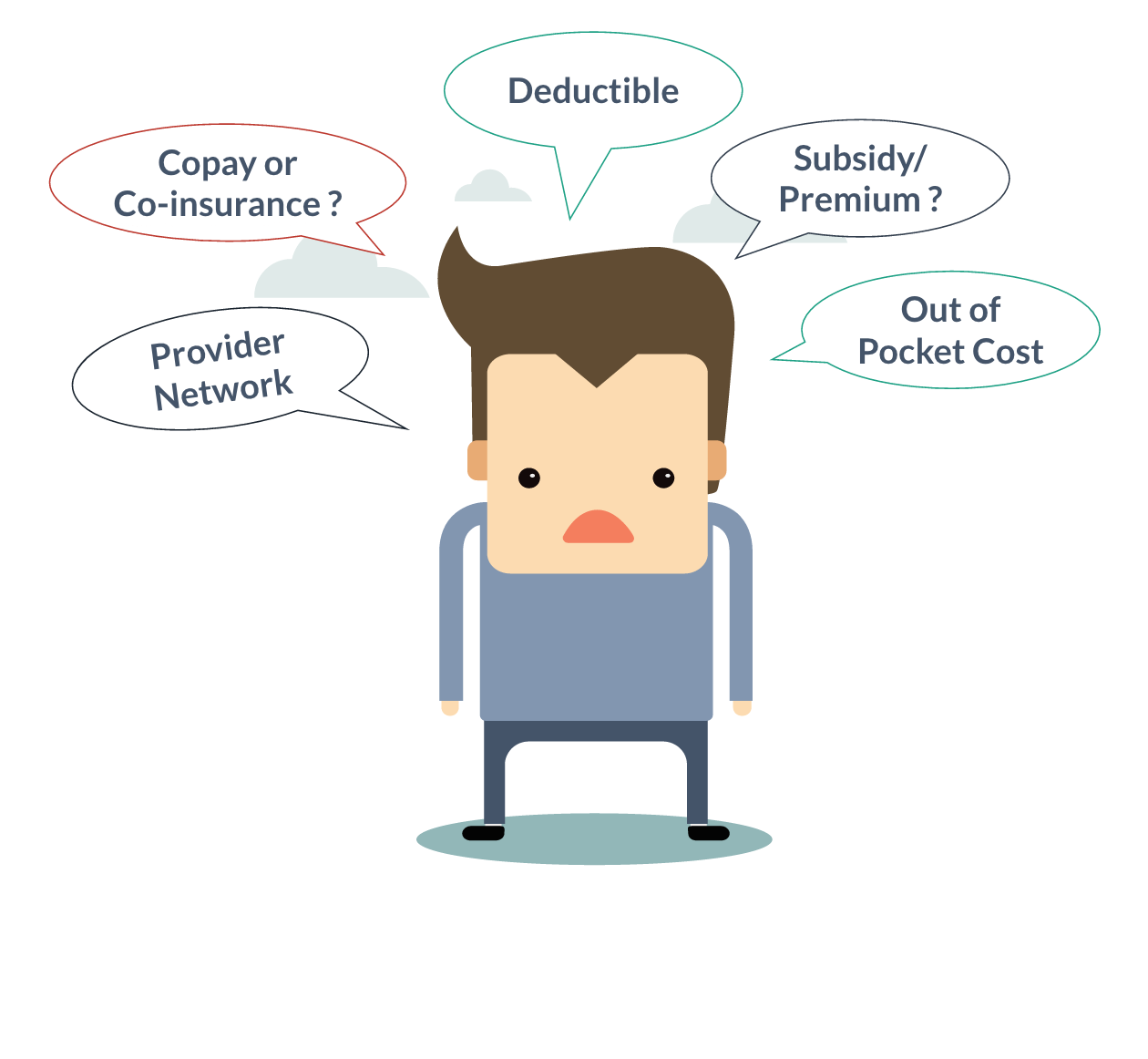
Federal and State healthcare exchanges find the data provided by insurers is incomplete and the only way to get the facts is to manually track it down and know to ask the right questions.
Doctors that are supposed to be in-network often aren't, specialists that are commonly required to treat diseases are not in the plan or too far away to be accessible.



Facets
Like brand, size, cost
and color become
insurer ,cost, co-pay & drugs
Recommendations
People like you chose...

Pickup Locations
Become Providers or
Specialists Near Me
Ranked Search & Ratings
Sponsored Searches, ratings for
insurers & providers
Most of the data sources for Semantic Health are comprised of the Public Use Files and data dictionaries
from CMS.gov Healthcare Marketplace Data Resources.
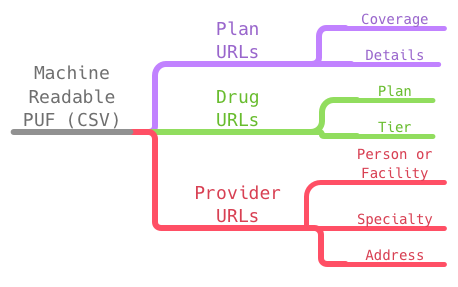
The main source is the Machine Readable URL PUF.
The MRURL PUF contains a row for each state and insurance provider with the URL to a JSON file that points to the Plans,
Providers and Formularies. This is the source of the physicians, addresses, plans for which they are in-network and accepting
patients and more. The Formularies contain the drugs that are covered in the plans, and the Plan JSON files contain the plan attributes.
The Machine Readable data constitutes a very broad but shallow tree structure where each branch is like the graph, below.
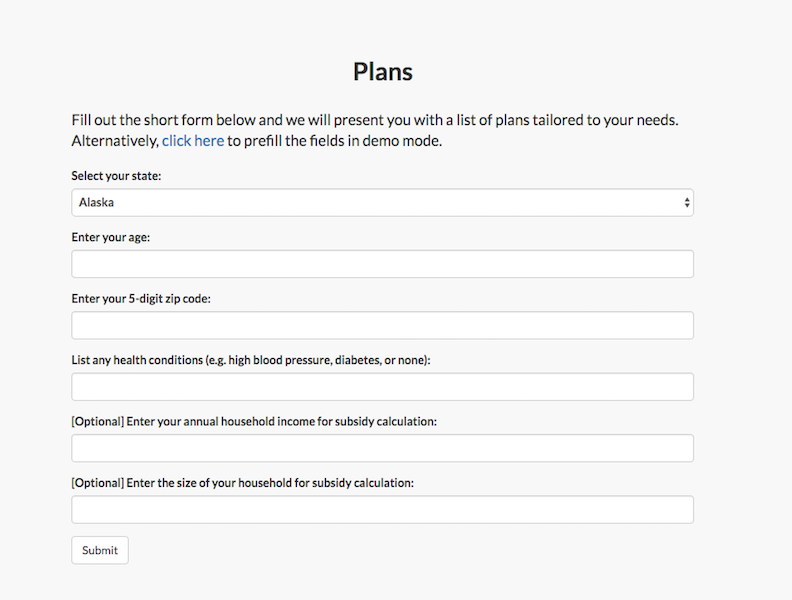
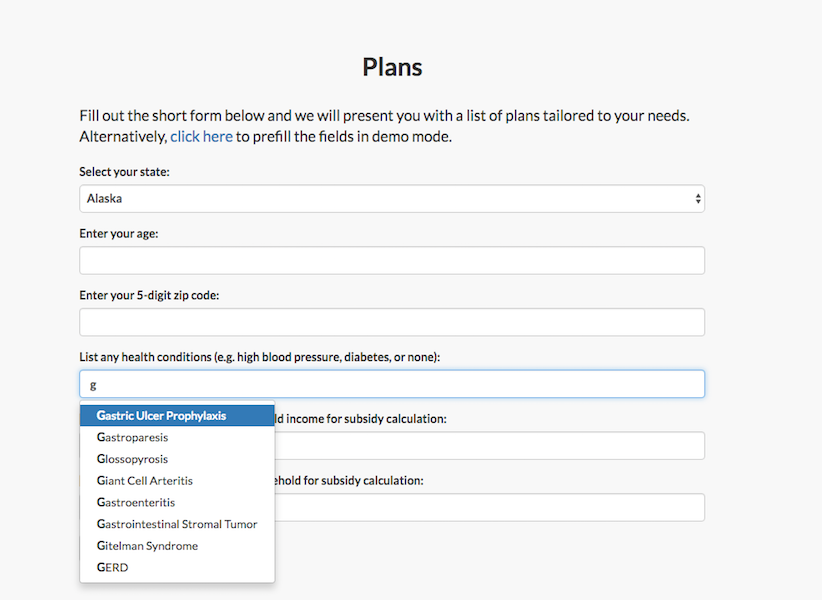
Semantic Health is a web application that helps people choose the right Obamacare plan. Our users interact with our product through this inteface only. We want this application to have a number of features that would help them accomplish their goals. Here is a list of requirements for the webpage:
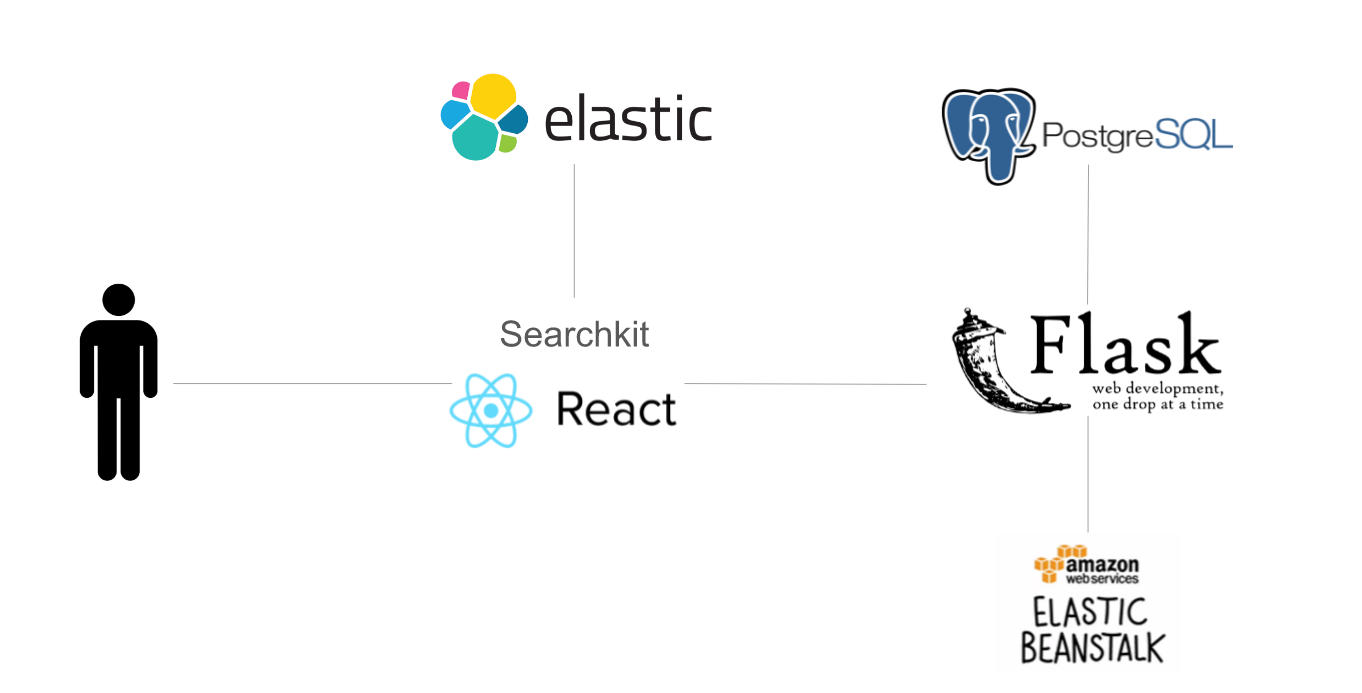
The above schematic shows all the components in our web application (see code for all components). All of the requirements were satisfied by this setup. Because the webserver is based on Flask (Python), it is very easy to get a production server up and running. Our web server manages all the backend web functionalities. It takes in the user's input, validates it, and sends the query to the frontend. It also has endpoints to log the visitor and clickstream data in a AWS RDS PostgreSQL database. The production server is deployed on AWS Elastic Beanstalk, which takes care of Apache web server administration and provides load balancing and instance autoscaling.
The frontend utilized many elements from searchkit, an elasticsearch UI framework based on React.js. We chose searchkit because it gave us a substantial headstart in the development of the UI. It is easy to use and extremely customizable. We were able to quickly build an interactive application which allows the user to do faceted search and input search. A custom rescore query component allows the results to be re-ranked based on the LETOR algorithm. Various event handlers were also present to assist in the recording of clickstream data.
Learn to Rank (LETOR) charaterizes search context for each user query, records click-through rate data (CTR), and builds a ranking model to capture the relationship between user preference and plan attributes, given a particular health status and realistic consideration. Plan attributes, including policy category, drug and provider coverage are extracted into feature vector. Pair-wise user preference is harvested based on reletive importance from browsing history. Plan returned by ElasticSearch will be adjusted at runtime by rankings from the similar context previously leanred by LETOR.
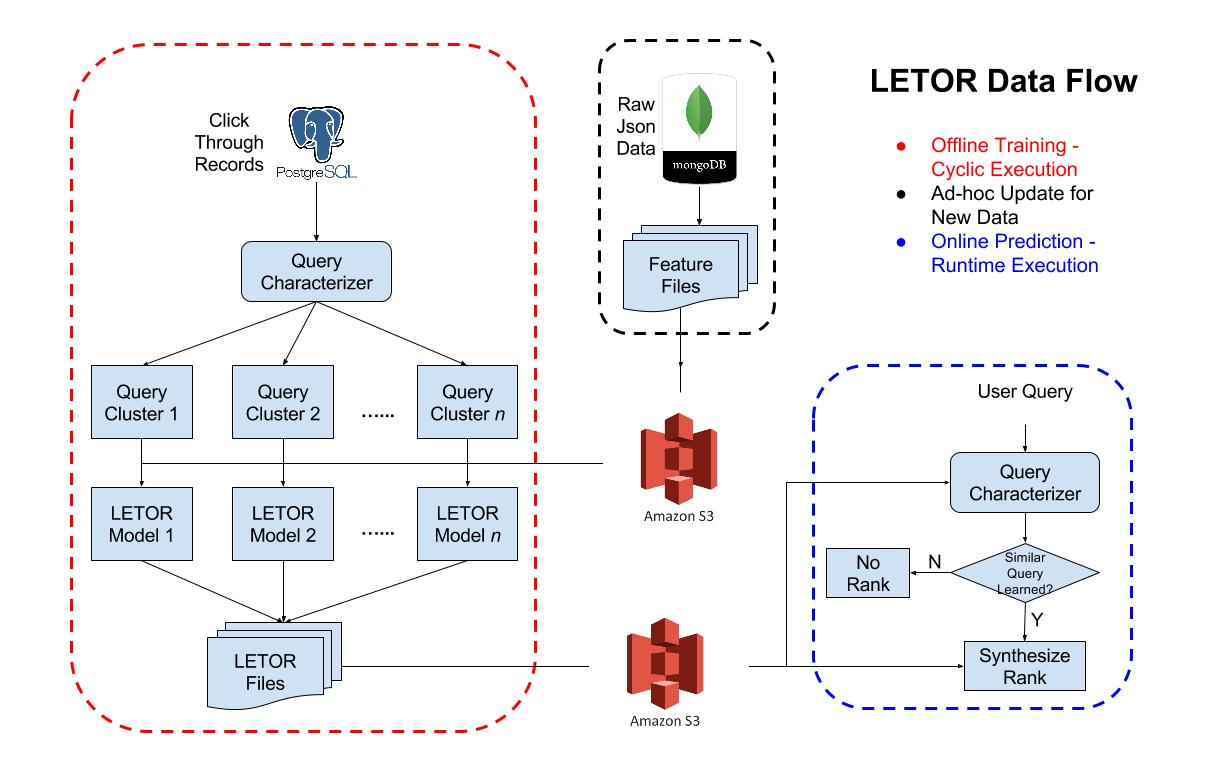
The data that drives the SemanticHealth.net site is served up by an Elasticsearch cluster. The raw data from the different data sources is stored and processed before being placed into an index. Healthcare plans are shown based on the adjusted rankings computed in the cluster.
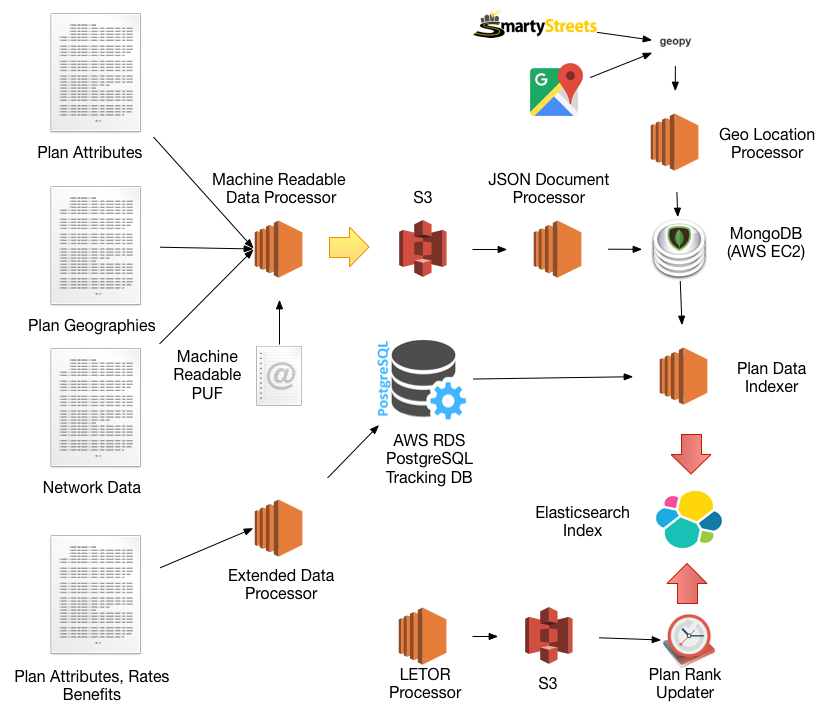
The Machine Readable Data Processor traverses the links of the Machine Readable PUF to download JSON files for the Provider, Plan and Formularies by state, insuror, and plan. These files are streamed to local files then transferred to S3 which makes it easier to re-ingest the data as needed. The Machine Readable URL PUF contains approximately 36K URLs that must be followed to get all the data for all the states that participate in the national ACA exchange at Healthcare.gov. The JSON files themselves range in size from a few hundred kilobbytes to several gigabytes each.
The Extended Data Processor processes a number of other data sources from CMS.gov to augment the core Plan, Provider, and Formulary data such as rate information, detailed plan attributes, co-pay and cost schedules. Logo URLs and drug information is scraped from the web and along with the intermediate data sources are stored in a PostgreSQL database for ease of filtering and selection.
The JSON Document Processor Tracking tables in a PostgreSQL database are used to track the state of downloads and processing making it simpler to re-start the process or pick up where left off if an error occurs. Ultimately the JSON files end up as MongoDB documents which allow for easy querying and augmentation with geo-location data.
The Plan Indexer assembles a document for each plan based on queries of the RDBMS and NoSQL databases and then uses the bulk indexing API to populate the documents for the index. The documents conform to a specific mapping to get the best performance for the Elasticsearch queries.
The Plan Rank Updater process runs every 3 hours to update the plan documents in the Elasticsearch index with the latest LETOR ranking data.
Besides the main data source used for the SemanticHealth project, from CMS.gov Healthcare MarketPlace Data Sets, we collected additional external data sets to further enhance search functionality and thereby improve overall user experience. Three of the external data sets we focused on were:
Drugs and associated Diseases/Conditions : This will allow users to search for plans by specific disease or condition they have. This is also used for an auto-complete feature, when users have to enter a disease/condition before searching for plans.
Geo-coding on over a million provider addresses : This will allow users to look up Providers that are near-by, based on the plan they selected.
Provider ratings (Yelp, HealthGrades, Vitals , UcompareHealthcare) : This data would enhance Learning and Ranking based on existing provider ratings (Note: We were not able to fully collect Provider Ratings due to some technical limitations we ran into - discussed below)
Drugs, Associated Conditions were scraped from following sources:
Data from Drugs.com was more comprehensive and included additional information related to impact of the drug on Pregnancy, Controlled Substance Abuse potential, Alcohol impact etc. These additional data elements can eventually be used to enhance Plan Search and provides additional features that can be used for LETOR or other Learning Algorithms.
Pulling Geocodes for over a millon providers proved to be a significant challenge at first. Most data sources and APIs out there had daily limitation on the number of free Geo pulls and additional pulls were prohibitively expensive, at least for the purposes of this project. In the end we were very excited that SmartyStreets (Thank you Jefferson!) offered to support our project by providing an unlimited pull license which we eventually used, to pull Geo Locations for over a million plus providers.
We use three different APIs to pull Geo Locations in a waterfall like method from three different sources listed below. Eventually those that return empty are saved separately to re-try at a later time.
Provider Ratings were scraped using project forked from PCPInvestigator, written by Tory Hoke.
The PCPInvestigator supports scraping from four different Health Care Provider rating sites:
Although the code is functional and tested, it has one major limitation with running on a large set of providers - the code uses Google to do a search and then scrapes the search results for any mention from one of the rating sites and then crawls the specific rating websites. Even with randomizing request headers and timing between request, search results returned 403 errors, mostly from Google blocking IP calls. So we were not able to fully utlize Provider ratings at this time, for the project.

All infrastructure built and managed with Vagrant and Ansible.
Amazon AWS services used:
IBM SoftLayer services used:
There are many possibilities for next steps for commercial and functional concerns.
Sponsored Search: Just as plan rankings can be adjusted to surface the best plan, rankings can be adjusted to coordinate with sponsors. This is a potential revenue stream with significant potential. Considering that the health insurance advertising expenditure is nearly $20 billion, just a percentage of that budget is significant. Considering the targeting capabilities of the Semantic Health platform insurance advertisers will get significantly more bang for their buck.
Search Data and Purchase Data: Semantic Health has data that's not available to anyone else - what people actually look for and consider when searching or shopping for a health insurance plan.
Chatbots: many common questions can be answered with chatbot technology used to hone the personalization experience of Semantic Health. Chatbots can significantly reduce the needs for human agents to step in and take over the more complex activities that may be required to finalize an insurance plan purchase.
Agents and Agency: by becoming a licensed insurance seller in the states that require it the Semantic Health data is extended beyond browsing to purchasing, increasing the value of the data and measurable results of advertising dollars. Human agents can assist with those more complex issues.
Free Form Query: combined with voice input, free form text queries provide a level of interaction unknown in the insurance industry today, all without human agency. The ability to pull out the key pieces of information in a statement like, "I'm a housewife from central Minnesota with 2 children, ages 4 and 6 and a husband with Type 2 diabetes" makes the entire experience much more user friendly. Leveraging various voice API's available to provide the voice to text combined with NLP processing to extract the meanings of the sentence we can leverage much of what already exists today"
Mobile: this seems like a no-brainer considering the ubiquitousness of mobile devices over computers. Combined with free form voice query this can be an amazingly effective means of shopping for insurance.
The SemanticHealth Project would not have been possible without the help and support of many people. We express our sincere thanks and deepest gratitude to all those that have helped us along the way.
David Steier & Coco Krumme : Thank you, for an awesome learning experience during the Capstone Class and also for your invaluable feedback, support and guidance during various stages of the project.
Jimi Shanahan - Thank you Jimi for the motiviation and unwavering support - you showed us how much farther we are able to go, and that's just the first mountain!
Safyre Anderson, Chris Dailey, Marjorie Sayer : Members of the original BayesHack 2016 Team that helped lay much of the ground work for this project
David Portnoy : Thank you for showing us just one way out of many we can contribute to make things better for everyone and the support and encouragement during the BayesHack 2016 HHS prompt.
Naama O. Pozniak (Owner @ A+ Insurance Service) : Thank you so much for the invaluable insight you provided into real issues people are facing today with ACA/Obamacare. This has helped us tremendously.
Jefferson from SmartyStreets.com : Thank you so much for allowing us to use SmartyStreets for GeoCoding over a million Provider addresses. Could not have done it without your help!
We are students from UC Berkeley's Master of Information and Data Science program. Signing up for health insurance from the Affordable Care Act (Obamacare) is difficult, and finding plans with preferred providers or drugs that you depend on involves significant work and expertise. We built Semantic Health with the goal to substantially improve the Obamacare enrollment process.